The Effect of Surprisal on the Decoding Performance of Neuronal Projections and Word Embeddings in the Semantic Domain
Finally, a PC analysis was used to dimensionally reduce θ along the neuronal dimension. This resulted in an intermediately reduced space consisting of five PCs each with a different dimensions, accounting for approximately half of the variance (71% for the semanticallyselective neurons). The dimensions of the space were preserved as a result of this procedure and the word shapes could be projected onto each of the PCs. To calculate the correlation between word projections derived from this PC space and word projections derived from English word space, we took the correlation between the two and looked at it across all word pairs. From a possible 258,121 word pairs (the availability of specific word pairs differed across participants), we compared the cosine distances between neuronal and word embedding projections.
We carried out a left-one-out cross-validation procedure to ensure our results weren’t driven by any particular participant. Here we repeated several of the analyses described above but now sequentially removed individual participants (that is, participants 1–10) across 1,000 iterations. If a particular group of participants disproportionally contributed to the results, their removal would be significant in affecting them. A χ2 test (P < 0.05) was used to further evaluate for differences in the distribution of neurons across participants.
We examined the effect of surprisal on the ability to predict the correct semantic domain on a per-word level. We used the SVC models that have been described and then divided decoding performances by words that showed high versus low surprisal. If the meaning representations of words are changed by sentence context, words that are more predictable on the basis of their preceding context should show a higher decoding performance.
in which P represents the probability of the current word (w) at position i within a sentence. A neural network was used to estimate P. Words that are more predictable on the basis of their preceding context would therefore have a low surprisal whereas words that are poorly predictable would have a high surprisal.
Modeling a Semantic Domain by Means of the Repeated Change and Classification Processes of Multiple Selective Neural Networks
It takes 100 times more to change a left than to change a right.
The neural activity is the same as the classification of individual words. The regularization version was set to 1. We used a linear kernel and ‘balanced’ class weight to account for the inhomogeneous distribution of words across the different domains. After the SVCs were modeled on the data, a decoding accuracy was determined by using words randomly sampling from the validation data. After randomly shuffling the labels on different permutations of the dataset, we created a null distribution and used the accuracy of the classification to calculate it. These models therefore together determine the most likely semantic domain from the combined activity patterns of all selective neurons. An empirical P value was calculated to include the permutations for which the decoding accuracy from the shuffled data was greater than the average score. The statistical significance was determined by the P value.
$$\mathop{min}\limits_{w,b,\zeta }\left(\frac{1}{2}{w}^{{\rm{T}}}{\rm{w}}+{\rm{C}}\mathop{\sum }\limits_{{\rm{i}}=1}^{{\rm{n}}}{\zeta }_{{\rm{i}}}\right)$$
Source: Semantic encoding during language comprehension at single-cell resolution
Semantic encoding during language comprehension at single-cell resolution. I. Analysis of the $rmSI$ of each neuron
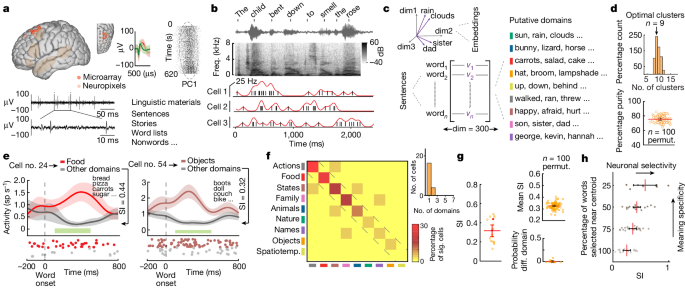
We determined the SI of each neuron in order to determine the degree to which it reacted to specific words. SI was defined by the ability of the cell to differentiate words, for example, food, compared to all other words. Each neuron had its SI calculated.
in which ({{\rm{FR}}}{{\rm{domain}}}) is the neuron’s average firing rate in response to words within the considered domain and ({{\rm{FR}}}{{\rm{other}}}) is the average firing rate in response to words outside the considered domain. The SI considers the difference in activity between the preferred semantic domain for each neuron and the others. The output of the function is dependent on two variables. An SI of 0 would mean that there is no difference in activity across any of the semantic domains (that is, the neuron exhibits no selectivity) whereas an SI of 1.0 would indicate that a neuron changed its action potential activity only when hearing words within one of the semantic domains.
$${\rm{SI}}=\frac{\left|{{\rm{FR}}}{{\rm{domain}}}-{{\rm{FR}}}{{\rm{other}}}\right|}{\left|{{\rm{FR}}}{{\rm{domain}}}+{{\rm{FR}}}{{\rm{other}}}\right|}$$
Source: Semantic encoding during language comprehension at single-cell resolution
Separability of clustered words in a naturalistic context using a word-list control and an extract from the Elvis Presley story
Each cluster was labelled on the basis of the number of words near the centroid. The resulting semantic domains reflected the optimal clustering of words based on their relatedness despite not all words fit within each domain. For comparison we also added a refined semantic domain called theExtended Data Table 2 in which the words provided within each cluster were reassigned or removed from them by two independent study members on the basis of their subjective semantic relatedness. There is a semantic domain under which all words that do not refer to an animal are removed.
The total number of words in the new clusters is k, and the number of clusters is 9. Finally, to confirm the separability of the clusters, we used a standard d′ analysis. The difference between the distance between words in a cluster and the distance between words in all other clusters, is estimated by the d′ metric. 2b).
The consistency of the responses was evaluated by introducing excerpt from the story narrative at the end of the recordings. Here, instead of the eight-word-long sentences, the participants were given a brief story about the life and history of Elvis Presley (for example, “At ten years old, I could not figure out what it was that this Elvis Presley guy had that the rest of us boys did not have”; Extended Data Table 1). This story was chosen because it was naturalistic, contained new words, and was different from the preceding sentences.
The sentence context was evaluated with a word-list control. The word lists contained the same words as the sentences they were presented to, but they were given in a random order, meaning that any effectlinguistic context had on lexico was lost.
The prefrontal cortex did not differentiate between words by their sounds. When a person heard the word ‘son’ in a sentence, for instance, words associated with family members lit up. The same words had an identical sound, but the neurons didn’t respond to them in a sentence.
The participants were presented with eight-word-long sentences (for example, “The child bent down to smell the rose”; Extended Data Table 1) that provided a broad sample of semantically diverse words across a wide variety of thematic contents and contexts4. To confirm that the participants were paying attention, a brief prompt was used every 10–15 sentences asking them whether we could proceed with the next sentence (the participants generally responded within 1–2 seconds).
The participants received the linguistic materials in audio format through a Python script. Audio signals were sampled at 22 kHz using two microphones (Shure, PG48) that were integrated into the Alpha Omega rig for high-fidelity temporal alignment with neuronal data. Audio recordings were annotated with semi-automated technology. Audio recordings were made at a 44 kmh sampling Frequency using a portable audio recorder and a microphone. To ensure the time alignment for each word token with the activity of the brain, the amplitude of the session recording and the pre-recorded linguistic material were cross-correlated. Each word token and its timing was verified manually. Together, these measures allowed for the millisecond-level alignment of neuronal activity with each word occurrence as they were heard by the participants during the tasks.
For the Neuropixels recordings, putative units were identified and sorted off-line using Kilosort and only well-isolated single units were used. We used Decentralized Registration of Electrophysiology Data (DREDge; https://github.com/evarol/DREDge) software and an interpolation approach (https://github.com/williamunoz/InterpolationAfterDREDge) to motion correct the signal using an automated protocol that tracked local field potential voltages using a decentralized correlation technique that realigned the recording channels in relation to brain movements31,66. The DREDge motion estimate allows us to track the recorded units over time using the continuous voltage data from the band. The motion-corrected interpolated signal was identified from the motion-corrected spikes using the Kilosort spike sorting approach and the phy for cluster curation. Here, an n-trode approach was used to optimize the isolation of single units and limit the inclusion of MUA67,68. Units with clear instability were removed and any longer periods of less than 20 sentences were excluded from analysis. In total, 3 recording sessions were carried out, for an average of 51.3 units per session per multielectrode array (Extended Data Fig. 1c,d
Microelectrode recording were performed in participants undergoing planned deep brain stimulator placement19,58. Recording the brain during a deep brain stimulator placement is usually done with the use of microelectrodearrays. Before clinical recordings and deep brain stimulator placement, recordings were transiently made from the cortical ribbon at the planned clinical placement site. The recording was centered in the superior anterior middle frontal gyrus of the languagedominant hemisphere. Here each participant’s computed tomography scan was co-registered to their magnetic resonance imaging scan, and a segmentation and normalization procedure was carried out to bring native brains into Montreal Neurological Institute space. Recording locations were confirmed and visualized on a standard three-dimensional rendered brain. The Montreal Neurological Institute coordinates for recordings are provided in Extended Data Table 1, top.
Once and only after a patient was consented and scheduled for surgery, their candidacy for participation in the study was reviewed with respect to the following inclusion criteria: 18 years of age or older, right-hand dominant, capacity to provide informed consent for study participation and demonstration of English fluency. To evaluate for language comprehension and the capacity to participate in the study, the participants were given randomly sampled sentences and were then asked questions about them (for example, “Eva placed a secret message in a bottle” followed by “What was placed in the bottle?”). Participants not able to answer all questions on testing were excluded from consideration. All participants gave informed consent to participate in the study and were free to withdraw at any point without consequence to clinical care. A total of 13 participants were enrolled (Extended Data Table 1). No participant blinding or randomization was used.
All procedures and studies were performed in accordance with the Massachusetts General Hospital Institutional Review Board and Harvard Medical School guidelines. All participants included in the study were scheduled to undergo planned awake intraoperative neurophysiology and single-neuronal recordings for deep brain stimulation targeting. Consideration for surgery was made by a multidisciplinary team including neurologists, neurosurgeons and neuropsychologists18,19,55,56,57. The decision to perform surgery was made on its own. The entry points and placements were not made from any study consideration, and were based solely on planned clinical targeting.
Williams and his colleagues got a chance to look at how the individual dopaminergic cells work. 10 people were recruited to have surgery for siblet, each with their brain electrodes implanted to find the source of their seizures. The researchers were able to record activity in the prefrontal cortex of each person with the help of the electrodes.
As participants listened to multiple short sentences containing a total of around 450 words, the scientists recorded which neurons fired and when. Williams says that around two or three distinct neurons lit up for each word, although he points out that the team recorded only the activity of a tiny fraction of the prefrontal cortex’s billions of neurons. The researchers then looked at the similarity between the words that activated the same neuronal activity.
To an extent, the researchers were able to determine what people were hearing by watching their neurons fire. Although they couldn’t recreate exact sentences, they could tell, for example, that a sentence contained an animal, an action and a food, in that order.
Humans have the same categories the brain assigns to words, as well as the same meanings, according to Williams.
Previous research2 has studied this process by analysing images of blood flow in the brain, which is a proxy for brain activity. Researchers could map word meaning to small parts of the brain.

