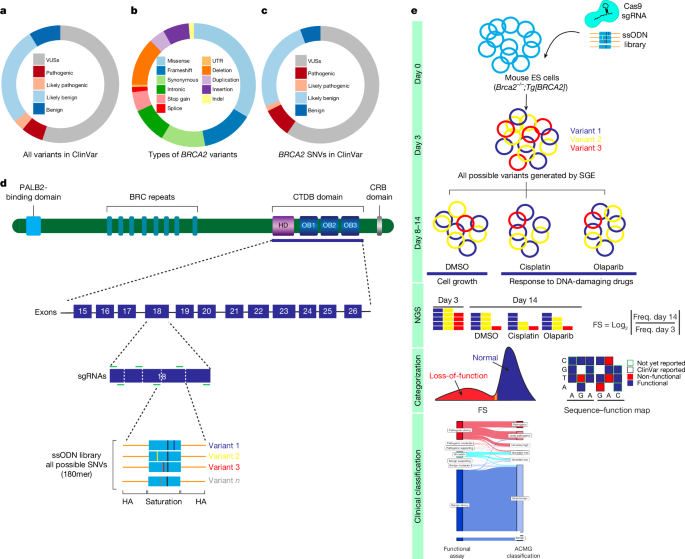
The evaluation and classification of BRCA2 variants is Functional Evaluation and Clinical
CADD-Splice-Improving Genome-Wide Variant Effect Prediction using Deep Learning-Derived Splice Scores
Rentzsch, P., Schubach, M., Shendure, J. & Kircher, M. CADD-Splice-improving genome-wide variant effect prediction using deep learning-derived splice scores. There are 31 articles in the Genome Med.
Hu, C. et al. Functional analysis and clinical classification of a number of germline BRCA2 missense variants. Am. It’s J. Hum. Genet. 111, 584–593 (2024).
Source: Saturation genome editing-based clinical classification of BRCA2 variants
An Automated Functional Assay for the Interpretation of Clinical Variants: “MutaX” and the AACR Project GENIE-2022. An application to the study of cancer genes
Tiberti, M. et al. “MutaX” is an automated pipeline for the in silico saturation mutagenesis of structures. Brief. The bbac074 was a Bioinformatics 23, and it was done in the year 2022,
de Bruijn, I. The analysis of longitudinal data from the AACR Project GENIE Biopharma Collaborative is done in cBioPortal. Cancer Res. 83 was published in 2023.
Sorrentino, E. et al. The integration of Var Some in an existing bioinformatic network is for automated ACMG interpretation of clinical variants. Exp. Rev. Med. There is a pharmaceutical. The article is titled “Sci. 25, 1–6”.
Walker, L. C. et al. Using the ACMG/AMP framework to capture evidence related to predicted and observed impact on splicing: recommendations from the ClinGen SVI Splicing Subgroup. Am. J. Hum. There is a human Genet. 110, 1046–1067 (2023).
Easton, D. F. et al. A systematic genetic assessment of 1,533 sequence variant of the genes for breast cancer-predisposition. Am. J. Hum. Genet. 81 was written in 2007.
The needles were used to find disease-causal variant in a wealth of genomic data. Nat. Rev. Genet. It was 11, 616–663 in 2011.
Tabet, D., Parikh, V., Mali, P., Roth, F. P. & Claussnitzer, M. Scalable functional assays for the interpretation of human genetic variation. Annu. Rev. Genet. A 56, 19′ 8.25 (2022).
Findlay, G. M., Boyle, E. A., Hause, R. J., Klein, J. C. & Shendure, J. Saturation editing of genomic regions by multiplex homology-directed repair. Nature 423, 120–123.
The Mouse stem cell-based functional Assay can evaluate the presence or absence of genetic alterations in the population. Nat. Med. 14, 875–881 (2008).
The identification of cancer genes that have been altered is done with base editing screens. In the next 5 years, Genome Biol. 22, 80.
Multi-Layered Assessment of the BRCA2 and DSS1 Modifications Associated with Fanconi Anemia on Human Genome Using CountReads
A P. and Mishra are both former professors at the University of Iowa. It is Dispensable for the interaction of BRCA2 andDSS1 to lead to recruitment at double strand breaks. Nat Commun. 13, 1751 was published in 1995.
V and Pejaver collaborated on a book. Calibration of computational tools for missense variant pathogenicity classification and ClinGen recommendations for PP3/BP4 criteria. Am. There’s a J. Hum. There is a Genet. 169, 203, 206, 207, 206, 207, 207, 207.
S E., and Brnich gave an assessment of their work. The ACMG/AMP Sequence variant interpretation framework has recommendations for applying the PS3/BS3 criterion. There are 12 published works in the Genome Med.
Biswas, K. et al. A comprehensive functional characterization of BRCA2 variants associated with Fanconi anemia using mouse ES cell-based assay. Blood 118, 2430–2442 (2011).
The book is titled Arnaudi, M. MAVISp: multi-layered assessment of variants by structure for proteins. The preprint was available on bioRxiv.
FASTQ files of sequenced samples from Illumina MiSeq or NextSeq assays were trimmed for adapter sequences using cutadapt (v.3.5). SeqPrep was able to convert the pairs into single reads. The single reads were aligned to the human reference genome (GRCh38) utilizing bwa-mem (v.0.7.17). After alignment, the custom-developed tool CountReads was used to do DNA-sequencing data analyses with a particular focus on the identification and characterization of mutations. CountReads included the preparation of reference amino acid and DNA sequences, validation of sequencing data integrity and precise trimming of reads to relevant regions. The method also differentiated between variant types and confirmed the presence of specific variants and aggregated and reported variant data. CountReads produced a variant call format (VCF) file, which was annotated using CAVA35. The Spliceai tool was used to evaluate the effects of observed SNVs.
The log2 ratio between the frequencies of D14 and D0 was used to measure the effect of each variant. A comparison of experimental D0 and D5 was used for positional adjustment. Variants with under-represented read counts (<10) at D0 and D5 were excluded from further analysis. log2 ratios of variants were linearly scaled within each exon across replicate experiments relative to median silent and median nonsense SNV values. The average score was calculated from all the non-missing values. The score was normalized using a linear scaling method which used median synonymous and nonsense values. After completion of all data cleaning and quality control, a raw functional score was available for 6,959 SNVs (Supplementary Table 3).
BRCA2 functionally PStrong missense alterations were mapped in the DBD using PyMol software. The Protein Data Bank source file (identifier 1MJE) was downloaded from the NCBI Molecular Modeling Database. The crystal structure of the complex was used to create three-dimensional structural modelling.
The Align-GVGD has a BRCA2 sequence. The 10 species used for sequence alignments are Homo sapiens, Pan troglodytes, Macaca mulatta, Rattus norvegicus, Canis familiaris,Bostaurus, Monodelphis Domestica, Gallus gallus, Xenopus laevis The analyses were done on the amino-acid residues that contained the functionally pathogenic variant. Align-GVGD26, AlphaMissense27 and Bayes-Del40 were used for in silico pathogenicity prediction.
SGE functional results were compared with those from other studies, including a BRCA2-deficient cell-based HDR assay7, a BRCA2-deficient cell line–based drug assay24, a prime-editing-based SGE study16 and a mouse embryonic-stem-cell-based functional analysis25.
The ACMG–AMP rule-based framework combines evidence from population, computational, predictive, segregating, functional, and other data and each contributing source weighted as either very strong or moderate. Variant classifications of benign, LB,LP and VUS9 are created by the combined data. In this study, ACMG–AMP scoring rules established by the ClinGen BRCA1/2 VCEP were used for clinical classification of BRCA2 DBD SNVs. The PS3/BS3 rule allowed the integration of the functional data from the BRCA2 into the classification model. The values for functional evidence were capped at +4 and –4 on the log scale to avoid LP or LB classification with functional evidence alone. The study was approved by the Western Institutional Review Board, which exempts the clinical testing cohort from review. The study uses the Detailed ACMG–AMP criteria in the Supplementary Methods.
LOH status for breast, ovarian, pancreatic, and prostate cancer tumours carrying germline BRCA2 DBD variants was acquired from tumour–normal paired sequencing using the IMPACT dataset32. The FACETS algorithm41 was used to determine LOH from matched tumour–normal pairs. Only tumour samples with >40% tumour content were included in the analysis.
Design and characterization of multiple Cas9 – sgRNA co-expression constructs for individual SGEs using NI-BamHI-HF-grown pSpCas9(BB)-2A
All data shown in this paper are provided with the explicit written consent of the study participants following approval from the institutional review boards.
HAP1 cells (Horizon Discovery) were maintained in IMDM with 10% FBS and 1% penicillin–streptomycin. For haploidy sorting, 1 107. HAP1 cells were resuspended in 5 mg ml–1 Hoechst 34580 (BD, 565877) and sorted at 4 °C. The cells were transfected with the drug Origene. All oligonucleotides and primers were synthesized by Integrated DNA Technologies.
Exons 15–26 were selected for SGE due to their role in the BRCA2DBD. The large exon size resulted in 14 SGE target regions, and was one of the reasons why exon 18 and 25 were split. Benchling was used to design multiple sgRNAs. sgRNA-annealed oligonucleotides were ligated into pSpCas9(BB)-2A-Puro (PX459 v.2.0) (Addgene, 62988) following BbsI (New England Biolabs, R0539L) digestion to create a Cas9–sgRNA co-expression construct for each individual SGE. For each SGE, 600−1,000 bp homologous arms upstream and downstream of the target region were amplified from wild-type HAP1 gDNA and cloned into a BamHI-HF-digested pUC19 vector using a NEBuilder HiFi DNA assembly Cloning kit. Cloned plasmid backbones were subjected to site-saturation mutagenesis by inverse PCR34 using mutagenized codon NNN primers for all possible nucleotide changes at each amino-acid position. A protospacer protection edit encoding a silent mutation was introduced by site-directed mutagenesis into the protospacer adjacent motif site or the sgRNA recognition site of each target region to prevent re-cutting by the Cas9–sgRNA after successful editing. Furthermore, a single 3-nucleotide mutation was introduced into the introns of each homologous arm to facilitate specific reamplification of the targeted DNA.